Remove unused thread_lock #912
Conversation
Signed-off-by: Damian Wrobel <dwrobel@ertelnet.rybnik.pl>
|
Can you elaborate slightly on what led you to conclude that this needed to change? |
I'm working on a rootless |
|
The intent of the lock is to ensure that non-realtime uspace gives a thread scheduling promise at least as strong as rate monotonic scheduling. From the message of the commit that added it in 2014, cbbd8e5:
Since your proposed change has to remove sites where the mutex was taken and released, I do not understand why you state it appears to be unused. The test called threads.0 is inteded to fail when the absence of rate monotonic scheduling is detected. Reportedly, the machinekit fork of LinuxCNC has given up the rate-monotonic guarantee. Before this can be done in LinuxCNC, the small number of components that create multiple realtime threads -- e.g., software stepgen and encoder, maybe that's about it? -- need to be checked for whether the way they communicate from "fast" to "slow" thread still works when rate monotonic scheduling is not guaranteed. |
|
I don't see how this could work as neither for a single thread or two threads invoking |
|
The locked section is from If you have information indicating there is a bug here, please provide it so we can find a solution together. |
I provided it in a previous post:
I also provided a link to the |
|
With respect, I do not think you have understood how the code works. However, it's also possible I'm overlooking something. More typically, you'll see code that looks like this: the lock and unlock appear in the same function, and the lock precedes the unlock. To see them in the opposite order looks pretty weird. Here's what the code is doing, albeit with more levels of function calls intervening: So the unlock is always preceded by a lock. The only exit is from "check for cancel", which occurs while the lock is not held. Whether the unlock is reached on the first iteration of the while loop or a subsequent iteration, it corresponds with a temporally previous lock from the same thread. However, the fact that this is spread across multiple functions in multiple source modules may have made the overall structure nonobvious. By ensuring that only one HAL realtime thread is never interrupted by another except during the thread's "wait", we provide for the simulator a stronger guarantee than we provide for RT, which is the rate monotonic guarantee. However, this stronger guarantee (and the structure providing it) should not be depended on; it provided what seemed to me a convenient implementation. |
|
is this related to #692 ? |
|
Not exactly, this is about non rt but that is about rt. |
|
Let's reuse annotations from my example: in your code: and then quote once more the following text from:
Now if you can fit all of them in one screen, it should be easier to notice that the code is wrong in You might try to solve that issue by adding It would interested to hear from you what's your observation if you use the |
Yes that's what the UI shows, but it's NOT an accurate reflection of the average. It's a form of the train arrival paradox https://math.stackexchange.com/questions/1446874/train-arrival-paradox
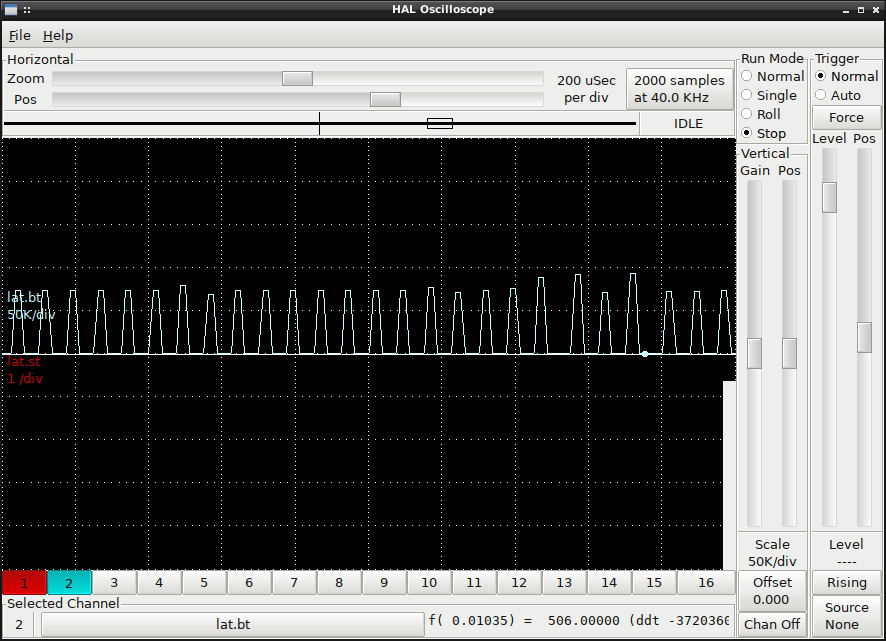
Here we see the "last base thread time" (hal signal name lat.bt) in halscope, so each successive value of it is captured. You can see that it is multimodal with many instances near 0 and many instances near 75000 but some going higher. Basically, we're asking for small sleeps that at least non-RT kernels with SCHED_OTHER scheduling will not furnish. So we sleep a lot longer than requested if we DO sleep, and skip sleeping at all when we know the next deadline has already passed: Now, it happens almost everytime that when we entered the else{} branch and DID sleep we will NOT sleep the next time, that causes the high value like 75000 to almost always be replaced by a low time like 250 when we hit the other path on the next run through. That doesn't mean that you can or should conclude that the average time is wrong. And, anyway, we don't keep any RT guarantees. You can also see that with e.g.,
As for the question of correct pthread mutex handling, I would like to understand whether
|
IMHO the simplified code perfectly depicts either error of undefined behaviour as per posix specification. As you closed this PR, I submitted #918 where you can see how this PR fits into a bigger picture. I would appreciate to get your feedback.
As as side effect #918 should also helps |
|
CBMC is a very useful program that can in certain circumstances prove programs are "correct". Among other things, it can check that the conditions of pthread mutexes are respected in all possible circumstances. I have modified the already simplified version of the mutex handling into a program suitable to feed to CBMC. According to cprover, this simplified version of what LinuxCNC does passes verification: And in particular, [pthread_mutex_unlock.assertion.1] must hold lock upon unlock: SUCCESS In case you would like to see how it detects a failure of the sort you are talking about, you can instead invoke it as You are also free to take a look at #916 in which the error-checking mode of mutexes is enabled, so that if my analysis is wrong a runtime error and abort will promptly result. |
I'm glad you can finally confirm the issue with the code.
Yeah, that seems to be seeing is believing approach, however, the real art is to believe (based on the specification only) not seeing. |
|
You misunderstand -- I believe CBMC proves the code in LinuxCNC is correct. "-DERROR" deliberately introduces incorrect code that is not reflective of LinuxCNC. |
This seems to be far fetched. In order to make such a statement you would first have to prove two following statements: Please try to answer to the following questions:
|
|
I do not "prove" that CBMC can detect all errors. However, CBMC's design is such that it SHOULD exhaustively prove that the specific kind of error we are discussing can never occur in the toy sample program. If it did not, then it would be an interesting example to the CBMC maintainers. CBMC does not "run" the software in a traditional way, rather it creates a model of the program and then proves that properties (such as pthread_mutex_unlock.assertion.1, that a lock is held when it is unlocked) are invariants of the program. In that way, it is exhaustive and is not dependent on timing properties. According to the CBMC authors on a different aspect of pthread correctness proving,
(I did not find a specific citation about the assertion known as pthread_mutex_unlock.assertion.1) CBMC is also cited a couple of times in Is Parallel Programming Hard, And, If So, What Can You Do About It? so it seems to be taken seriously as a tool for this purpose by those who are expert in the field. As to your specific questions:
I do not believe it is productive to continue this discussion without additional information or a new perspective. I have provided the best information I can and honestly I remain bewildered that we cannot agree about this. I am going to seek someone else without a vested interest for their views on this matter, and I suggest you do the same; it's clear that the two of us are not going to come to an understanding through more discussion. |
Unfortunately, the You would be surprised how often this occurs in reality. Here is the session recorded from In order to reproduce it, please run in one console: while on the other console attach
I'm hopping this should finally convince you and I'm partially surprised that it was so difficult to understand why this code is wrong. |
|
It is no surprise that multiple threads can be within the line range 1091..1105 (in the region from the unlock to the lock) because this is the range of lines NOT protected by the lock. For instance, say your two threads had a period of "1 day" and "1 week" -- most of the time, your debugger would show that they were both in the sleep call. This could happen with the following sequence of events:
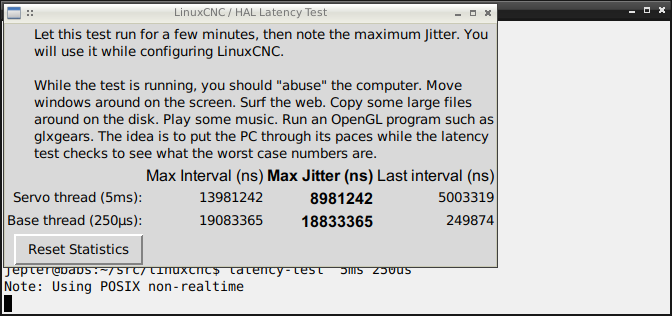
Even with 1ms & 25us threads in latency-test, most of the time will be spent in testcancel and sleep, because the "work" is on the order of 300ns. You may want to reflect on your dismissal of #916 (that the addition of error-checked mutexes proves nothing, it could just be that the situation is infrequent) in light of your new claim that the error condition occurs readily under the debugger. Can all these be true?
The important thing we can say is: it is a precondition of Posix::wait that the lock be held by this thread. If this precondition does not hold, then we will unlock a not-locked lock. Which paths arrive at unlock? Returning to the simplified program, which you considered to be equivalent to what LinuxCNC was doing, let's look at it again: Here, the precondition changes to "the lock is held at the top of the while-loop". There are two paths to the top of the while loop, from line 2 or from line 9. Both paths take the lock. Therefore, the precondition holds. Let's look at it another way, hopefully as a series of transformations we can agree preserve the "lock is held by this thread when unlock is called" invariant. Basic: function executes linearly, critical section, no loopCritical section is repeated in a loop until canceledNote the sequence of calls is: lock / unlock / testcancel Roll body of while loopNote that the sequence is still lock / unlock / testcancel. |
It proves that you were wrong saying that it cannot occur.
It could be equally true that, error-checking in mutexes simply cannot detect this situation or it's not properly implemented, if at all. That's why it's so important to use the API according to the specification and not rely on any extra tool or error checking.
In my opinion it might happens, with a high probability, up to Off topic, I'm getting close to the beginning of my holiday, so I assume you can understand that we won't be able to continue this interesting discussion indefinitely. |
How can this occur, when a thread's arrival at line 1090 requires that it hold the lock? Why should two threads both seen at line 1091 at the same time be taken as evidence of activity at line 1090 at the same time? Let's continue looking at the simplified code I offered previously: Since you didn't specifically comment, I don't know whether you consider this to contain the essence of the LinuxCNC code. I believe f2 and f3 are equivalent, and that f3 is equivalent to what we already agreed was equivalent. If you don't see to the equivalence at some step or other, then it might be fruitful to focus on why that is, because it could help get at the root of our disagreement. A precondition to arriving at line 4 is passing line 3. But a postcondition to completing line 3 is that this thread owns the lock. Therefore, the precondition to unlock() -- namely, that this thread owns the lock -- is met. Nothing stops two threads from being at other lines outside of 3..4, so no requirement is violated if both are seen at line 2, both at line 5, etc. Enjoy your vacation. Let me close with some suggestions for moving beyond this even if we can't have a meeting of the minds about how the code functions.
|
Signed-off-by: Damian Wrobel dwrobel@ertelnet.rybnik.pl